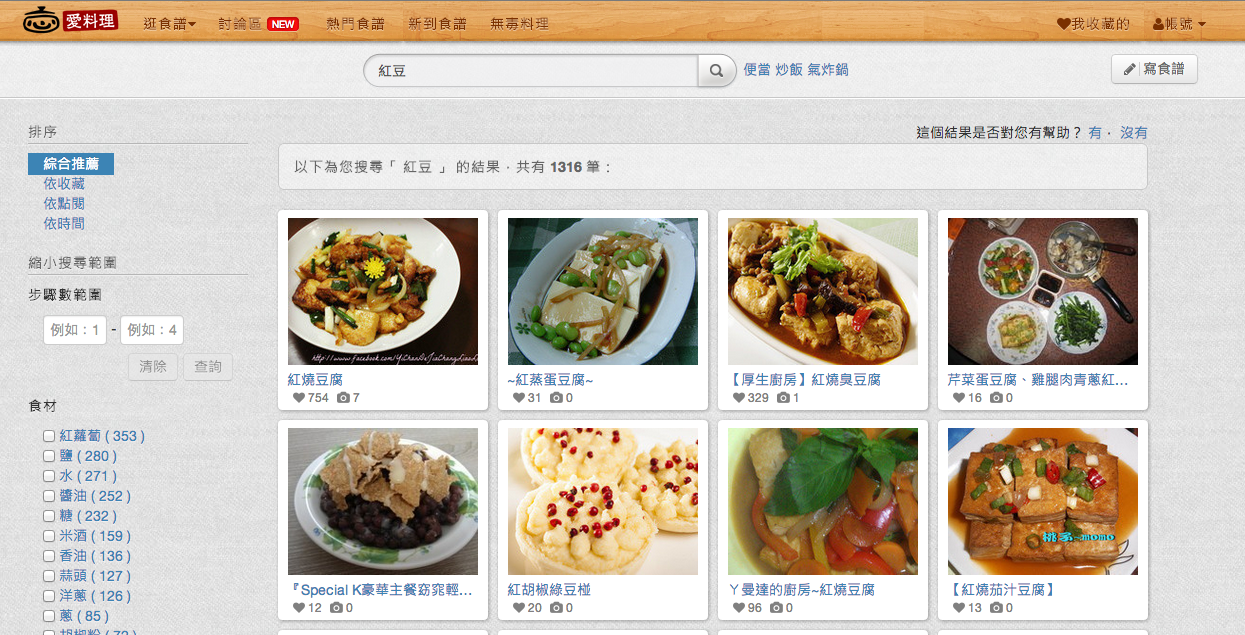
 於是我成了紅豆控,開始思索以上這個問題該如何解決
於是我成了紅豆控,開始思索以上這個問題該如何解決
Polydice 使用 Elasticsearch + Tire 作為搜尋引擎。原本套用mmseg 的 plugin,但似乎斷詞以 unigram 為主,以至於搜尋紅豆會找成紅燒豆腐。
*
計算n-gram的詞頻(term frequency)
n-gram指得是以n個字為單位做斷字,如:「抹茶冰淇淋很好吃」依照bi-gram做斷字會被斷成「抹茶」、「茶冰」、「冰淇」、「淇淋」、「淋很」、「很好」、「好吃」,我們可以發現有幾個字是有意義的,像是「抹茶」和「好吃」。依照中文字的特性,我們通常會取bi-gram和tri-gram為主,但此次分析的文集(corpus)為中文食譜,考量到食譜可能會有four-gram,如:「無鹽奶油」、「低筋麵粉」等,因此我依序將文集做four-gram、tri-gram、bi-gram和uni-gram斷字處理並計算出詞頻。
*
選取詞頻門檻(threshold)並過濾無意義的文字(stop-words)
依據Zipf’s Law,我們可以知道字的排名與詞頻指數成反比,且排名特別高和特別低的可能為較不顯著、無代表性的文字,如:「與」、「和」的詞頻特別高卻沒有特殊含意,「Parmesan」(一種起司)就只有出現一次代表說可能大多數使用者不會輸入或知悉這項材料。因此,此步驟主要就是要過濾這些較不顯著的文字,留下大多數有意義的文字來供使用者搜尋之用。一開始設的門檻分別為從four-gram到uni-gram分別設10、15、20和90,取出的文字看起來是有意義的但會遇到一個問題:在bi-gram的步驟中,同時留下「巧克」和「克力」兩個字,但其實這應該屬於tri-gram中的「巧克力」,因此我多了一個判斷式:若n-gram中包含於(n+1)-gram的詞且兩者詞頻相近的話及過濾掉n-gram的字詞。又因為要考量到(n+1)-gram,所以我取到five-gram以方便進行篩選。最後,為了提高本詞庫的精確度,我將門檻全設為2,也就是說:刪除僅出現一次的字。 [選詞結果 | 詞庫索引]
*
將食譜依詞庫標籤並建立反索引(inverted index)
詞庫建立完成後,將每一比食譜與詞庫中的字詞進行比對,有出現的及給予標籤,並記錄該字詞出現在哪些食譜之中,以加速未來搜尋之用。 [反索引]
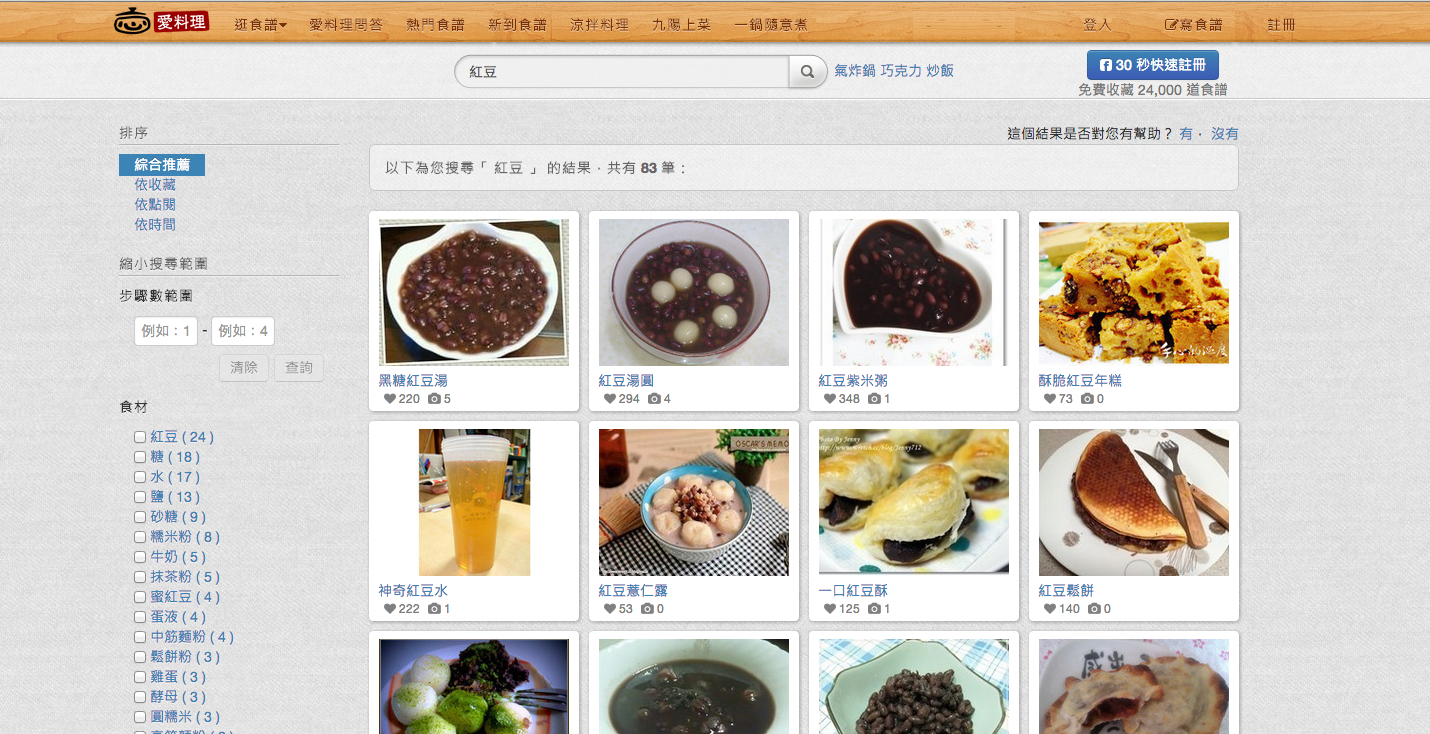
把plugins 改成 ik 並套用該詞庫後,效果明顯改善許多。